1/1
豆瓣top100电影信息爬虫
用python爬虫豆瓣电影TOP100的简易信息
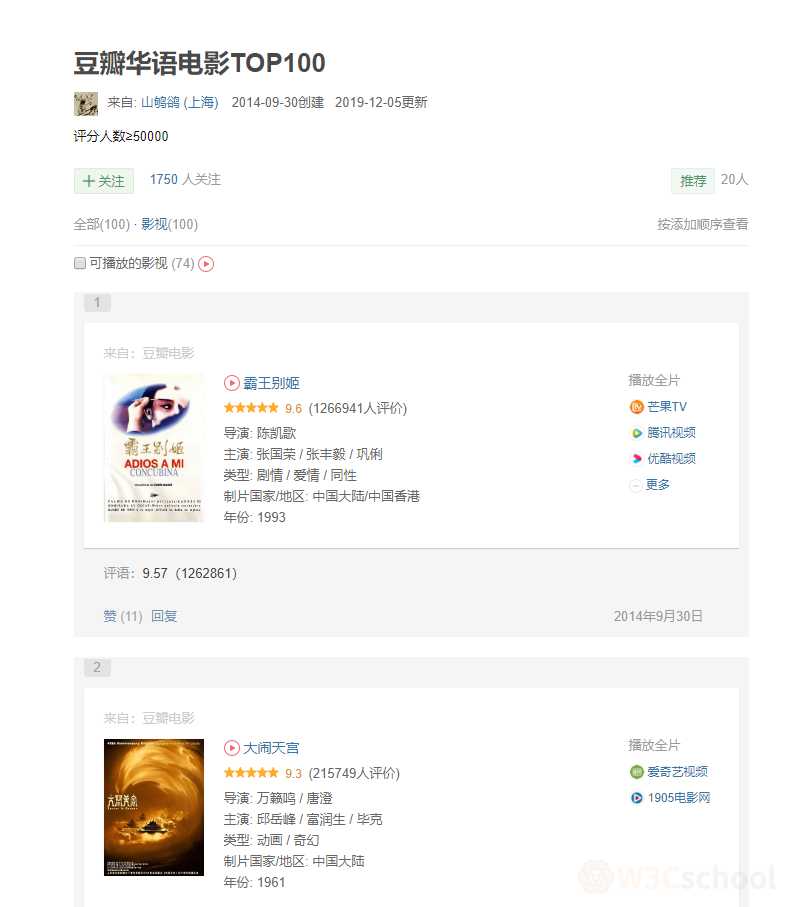
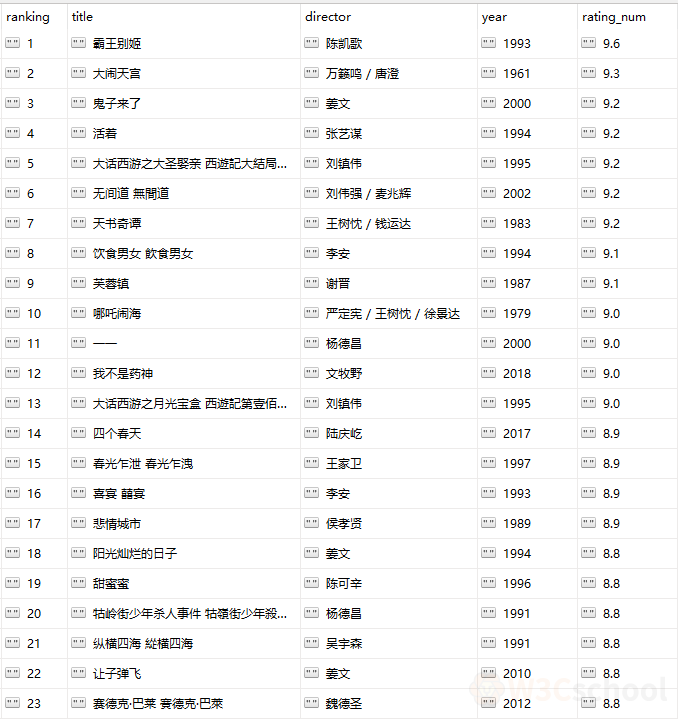
要收集的信息包括:每部电影的标题、导演、上映年份、评分。
先分析一下网页结构,然后用 xpath 解析出想要的数据,接着保存到 mongodb 数据库中:
import requests
from lxml import etree
from chardet import detect
from pymongo import MongoClient
def douban_spider():
"""
豆瓣爬虫调度器
:return: None
"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
# 总公有4页,每页间隔25
for i in range(0, 101, 25):
# 用 requests 发送请求获取 html 文档
url = 'https://www.douban.com/doulist/13704241/?start=' + str(i)
print(url)
response = requests.get(url, headers=headers)
# 用 xpath 规则解析 html 文档
html = response.content.decode(detect(response.content).get('encoding'))
tree = etree.HTML(html)
page_parser(tree)
def page_parser(tree):
"""
页面解析器
:return:
"""
for item in tree.xpath('//div[@class="article"]/div[@class="doulist-item"]'):
data = dict()
# 排名
data['ranking'] = item.xpath('.//div[@class="hd"]/span/text()')[0]
# 标题
data['title'] = ''.join(item.xpath('.//div[@class="bd doulist-subject"]/div[@class="title"]/a/text()')).strip()
abstract = item.xpath('.//div[@class="abstract"]/text()')
if abstract:
# 导演
data['director'] = ''.join(abstract[0]).strip().split(':')[-1].strip()
# 上映年份
try:
data['year'] = ''.join(abstract[4]).strip().split(':')[-1].strip()
except Exception as e:
data['year'] = ''.join(abstract[3]).strip().split(':')[-1].strip()
# 评分
rating_num = item.xpath('.//span[@class="rating_nums"]/text()')
if rating_num:
data['rating_num'] = rating_num[0]
save_data(data)
def save_data(data):
"""
将爬取的数据写入 mongodb 数据库
:return: bool 数据是否保存成功
"""
client = MongoClient()
db = client.douban
collection = db['top100']
collection.insert_one(data)
def main():
douban_spider()
if __name__ == '__main__':
main()最后输出到douban_movie.csv里,打开后是这样的~