


手机也能上课

1/5
什么是爬虫
什么是网络爬虫
网络爬虫(Web Crawler),又称网络蜘蛛(Web Spider)或网络机器人(Web Robot),是一种自动访问互联网并提取信息的程序或脚本。它们通常被用于搜索引擎、数据采集和信息检索等领域。网络爬虫通过模拟人类用户的浏览行为,自动访问网页,下载内容,并将其存储以供后续分析和使用。
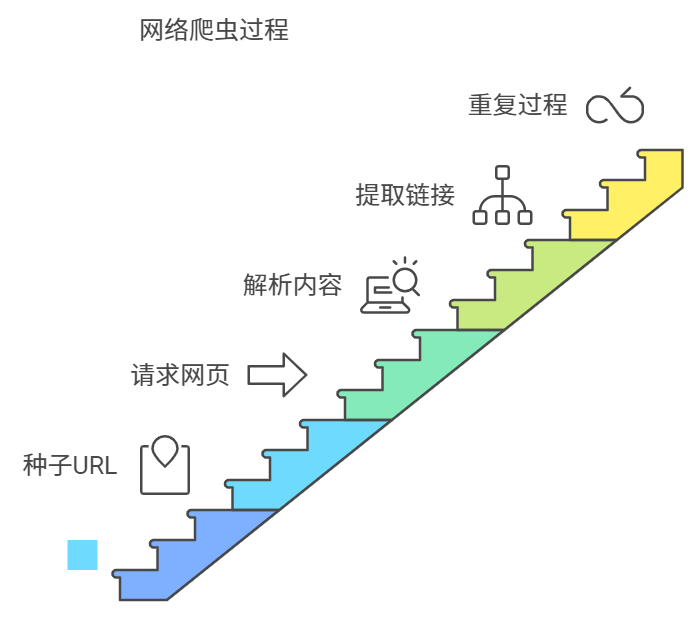
网络爬虫的工作原理主要包括以下几个步骤:
- 种子URL:爬虫从一组初始的URL(种子URL)开始,这些URL是爬虫要访问的网页地址。
- 请求网页:爬虫向这些URL发送HTTP请求,获取网页的HTML内容。
- 解析内容:爬虫解析下载的网页内容,提取出有用的信息,如文本、图片、链接等。
- 提取链接:爬虫从网页中提取出新的链接,并将这些链接加入待访问的URL列表中。
- 重复过程:爬虫重复上述步骤,直到达到预设的停止条件,例如抓取的网页数量、时间限制或特定的深度。
网络爬虫的应用非常广泛,包括但不限于:
- 搜索引擎:如Google、Bing等使用爬虫来索引网页,以便用户能够快速找到所需信息。
- 数据分析:企业和研究人员使用爬虫收集数据,以进行市场分析、舆情监测等。
- 内容聚合:一些网站使用爬虫从多个来源收集信息,提供综合服务。
然而,网络爬虫的使用也面临一些挑战和道德问题,例如:
- 网站的robots.txt:许多网站会通过robots.txt文件来限制爬虫的访问,爬虫应遵守这些规则。
- 法律和隐私:爬虫在抓取数据时需要遵循相关法律法规,避免侵犯用户隐私或知识产权。
总之,网络爬虫是一种强大的工具,能够帮助我们从浩瀚的互联网中提取有价值的信息,但在使用时也需要遵循一定的规范和道德标准。