python怎么爬取豆瓣电影TOP250数据?
2021-07-16 15:25:52
浏览数 (3405)
对于爬虫的学习而言,很多时候学习爬虫的解决方案比复制代码更有用,而计算机领域有这么一段著名的话“talk is cheap,show me code”告诉我们一个真理,代码比苍白的语言更有力。接下来我们通过一个python爬虫源码,来学习一些python怎么爬取豆瓣数据,并将其爬取的数据存储下来的代码吧。
在执行程序前,先在MySQL中创建一个数据库"pachong"。
import pymysql
import requests
import re
#获取资源并下载
def resp(listURL):
#连接数据库
conn = pymysql.connect(
host = '127.0.0.1',
port = 3306,
user = 'root',
password = '******', #数据库密码请根据自身实际密码输入
database = 'pachong',
charset = 'utf8'
)
#创建数据库游标
cursor = conn.cursor()
#创建列表t_movieTOP250(执行sql语句)
cursor.execute('create table t_movieTOP250(id INT PRIMARY KEY auto_increment NOT NULL ,movieName VARCHAR(20) NOT NULL ,pictrue_address VARCHAR(100))')
try:
# 爬取数据
for urlPath in listURL:
# 获取网页源代码
response = requests.get(urlPath)
html = response.text
# 正则表达式
namePat = r'alt="(.*?)" src='
imgPat = r'src="https://atts.w3cschool.cn/attachments/(.*?)" class='
# 匹配正则(排名【用数据库中id代替,自动生成及排序】、电影名、电影海报(图片地址))
res2 = re.compile(namePat)
res3 = re.compile(imgPat)
textList2 = res2.findall(html)
textList3 = res3.findall(html)
# 遍历列表中元素,并将数据存入数据库
for i in range(len(textList3)):
cursor.execute('insert into t_movieTOP250(movieName,pictrue_address) VALUES("%s","%s")' % (textList2[i],textList3[i]))
#从游标中获取结果
cursor.fetchall()
#提交结果
conn.commit()
print("结果已提交")
except Exception as e:
#数据回滚
conn.rollback()
print("数据已回滚")
#关闭数据库
conn.close()
#top250所有网页网址
def page(url):
urlList = []
for i in range(10):
num = str(25*i)
pagePat = r'?start=' + num + '&filter='
urL = url+pagePat
urlList.append(urL)
return urlList
if __name__ == '__main__':
url = r"https://movie.douban.com/top250"
listURL = page(url)
resp(listURL)结果如下图:
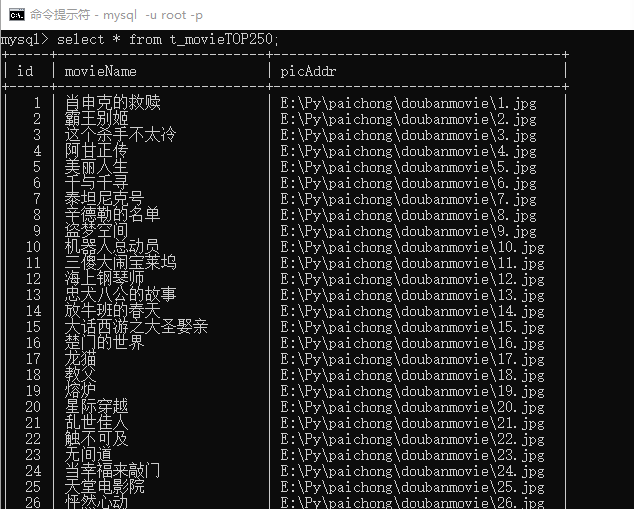
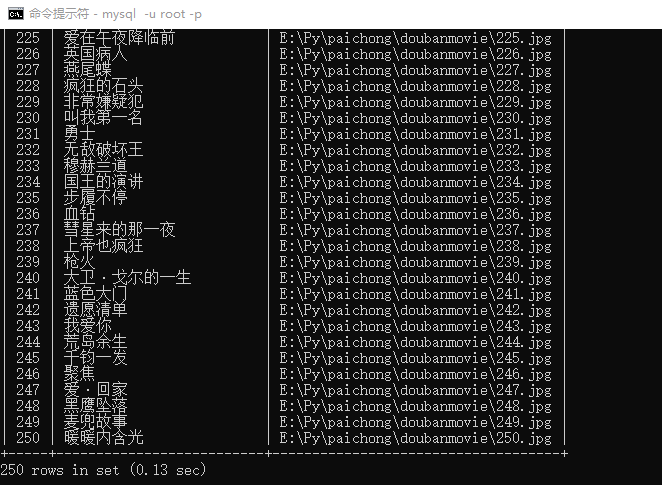
小结
以上就是python怎么爬取豆瓣数据的详细内容,更多关于python爬虫的学习材料请多多关注W3Cschool相关文章!