从小白到高手,你需要理解同步与异步(内含10张图)
在这篇文章中我们来讨论一下到底什么是同步,什么是异步,以及在编程中这两个极为重要的概念到底意味着什么。
相信很多同学遇到同步异步这两个词的时候大脑瞬间就像红绿灯失灵的十字路口一样陷入一片懵逼的状态:

是的,这两个看上去很像实际上也很像的词汇给博主造成过很大的困扰,这两个词背后所代表的含义到底是什么呢?
我们先从工作场景讲起。
苦逼程序员
假设现在老板分配给了你一个很紧急并且很重要的任务,让你下班前必须完成(万恶的资本主义)。为了督促进度,老板搬了个椅子坐在一边盯着你写代码。
你心里肯定已经骂上了,“WTF,你有这么闲吗?盯着老子,你就不能去干点其他事情吗?”
老板仿佛接收到了你的脑电波一样:“我就在这等着,你写完前我哪也不去,厕所也不去。”
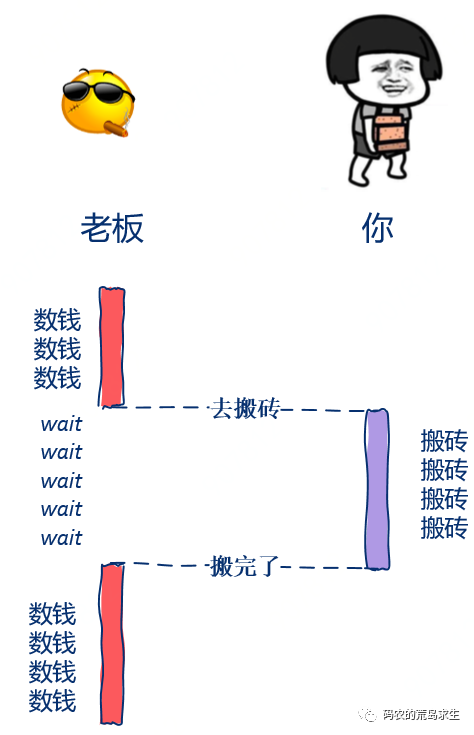
这个例子中老板交给你任务后就一直等待,什么都不做直到你写完,这个场景就是所谓的同步。
第二天,老板又交给了你一项任务。
不过这次就没那么着急啦,这次老板轻描淡写,“小伙子可以啊,不错不错,你再努力干一年,明年我就财务自由了,今天的这个任务不着急,你写完告诉我一声就行”。
这次老板没有盯着你写代码,而是转身刷视频去了,你写完后简单的和老板报告一声“我写完了”。
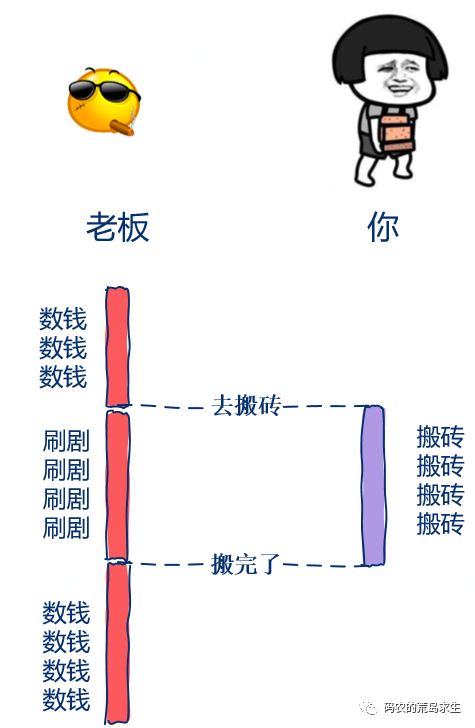
在这个例子中老板交代完任务后不再一直等着什么都不做而是就去忙其它事情,你完成任务后简单的告诉老板任务完成,这就是所谓的异步。
值得注意的是,在异步这种场景下重点是在你写代码的同时老板在刷剧,这两件事在同时进行,而不是一方等待另一方,因此这就是为什么一般来说异步比同步高效的本质所在,不管同步异步应用在什么场景下。
我们可以看到同步这个词往往和任务的“依赖”、“关联”、“等待”等关键词相关,而异步往往和任务的“不依赖”,“无关联”,“无需等待”,“同时发生”等关键词相关。
By the way,如果遇到一个在身后盯着你写代码的老板,三十六计走为上策。
打电话与发邮件
作为一名苦逼的程序员是不能只顾埋头搬砖的,平时工作中的沟通免除不了,其中一种高效的沟通方式是吵架。。。啊不,是电话。

通常打电话时都是一个人在说另一个人听,一个人在说的时候另一个人等待,等另一个人说完后再接着说,因此在这个场景中你可以看到,“依赖”、“关联”、“等待”这些关键词出现了,因此打电话这种沟通方式就是所谓的同步。
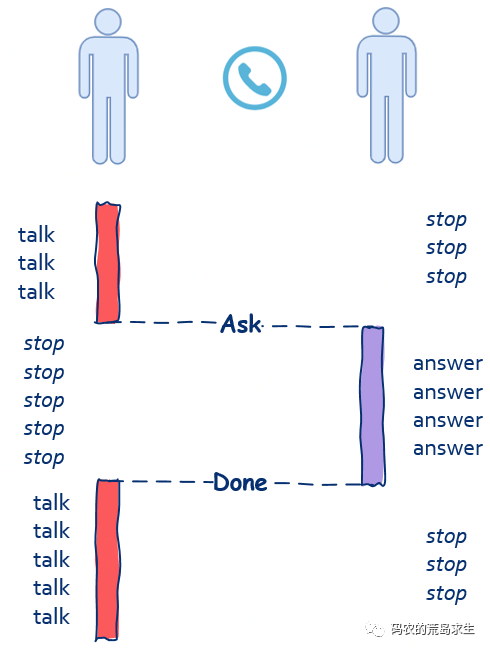
另一种码农常用的沟通方式是邮件。
邮件是另一种必不可少沟通方式,因为没有人傻等着你写邮件什么都不做,因此你可以慢慢悠悠的写,当你在写邮件时收件人可以去做一些像摸摸鱼啊、上个厕所、和同时抱怨一下为什么十一假期不放两周之类有意义的事情。
同时当你写完邮件发出去后也不需要干巴巴的等着对方回复什么都不做,你也可以做一些像摸鱼之类这样有意义的事情。

在这里,你写邮件别人摸鱼,这两件事又在同时进行,收件人和发件人都不需要相互等待,发件人写完邮件的时候简单的点个发送就可以了,收件人收到后就可以阅读啦,收件人和发件人不需要相互依赖、不需要相互等待。
你看,在这个场景下“不依赖”,“无关联”,“无需等待”这些关键词就出现了,因此邮件这种沟通方式就是异步的。
同步调用
现在终于回到编程的主题啦。
既然现在我们已经理解了同步与异步在各种场景下的意义(I hope so),那么对于程序员来说该怎样理解同步与异步呢?
我们先说同步调用,这是程序员最熟悉的场景。
一般的函数调用都是同步的,就像这样:
funcA() {
// 等待函数funcB执行完成
funcB();
// 继续接下来的流程
}
funcA 调用 funcB,那么在 funcB 执行完前,funcA 中的后续代码都不会被执行,也就是说 funcA 必须等待 funcB 执行完成,就像这样:
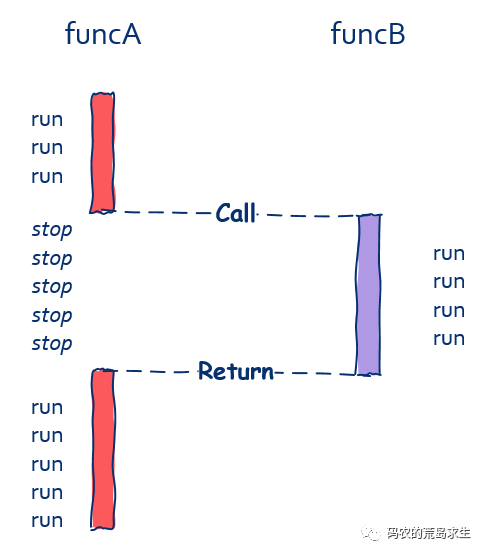
从上图中我们可以看到,在funcB运行期间funcA什么都做不了,这就是典型的同步。
注意,一般来说,像这种同步调用,funcA和funcB是运行在同一个线程中的,这是最为常见的情况。
但值得注意的是,即使运行在两个不能线程中的函数也可以进行同步调用,像我们进行 IO 操作时实际上底层是通过系统调用的方式向操作系统发出请求的,比如磁盘文件读取:
read(file, buf);
这就是阻塞式 I/O,在read函数返回前程序是无法继续向前推进的
read(file, buf);
// 程序暂停运行,
// 等待文件读取完成后继续运行如图所示:
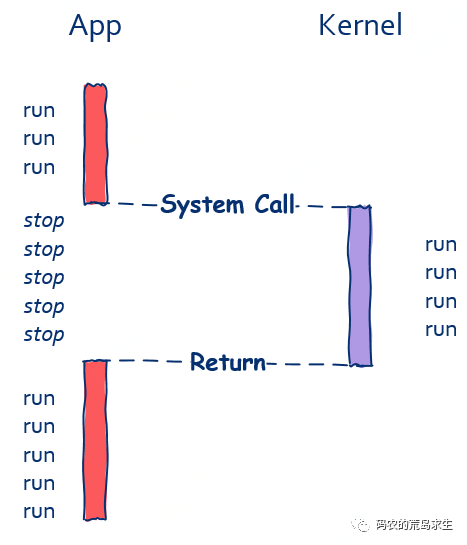
只有当read函数返回后程序才可以被继续执行。
注意,和上面的同步调用不同的是,函数和被调函数运行在不同的线程中。
因此我们可以得出结论,同步调用和函数与被调函数是否运行在同一个线程是没有关系的。
在这里我们还要再次强调,同步方式下函数和被调函数无法同时进行。
同步编程对程序员来说是最自然最容易理解的。
但容易理解的代价就是在一些场景下,同步并不是高效的,原因很简单,因为任务没有办法同时进行。
接下来我们看异步调用。
异步调用
有同步调用就有异步调用。
如果你真的理解了本节到目前为止的内容的话,那么异步调用对你来说不是问题。
一般来说,异步调用总是和 I/O 操作等耗时较高的任务如影随形,像磁盘文件读写、网络数据的收发、数据库操作等。
我们还是以磁盘文件读取为例。
在read函数的同步调用方式下,文件读取完之前调用方是无法继续向前推进的,但如果read函数可以异步调用情况就不一样了。
假如read函数可以异步调用的话,即使文件还没有读取完成,read函数也可以立即返回。
read(file, buff);
// read函数立即返回
// 不会阻塞当前程序就像这样:
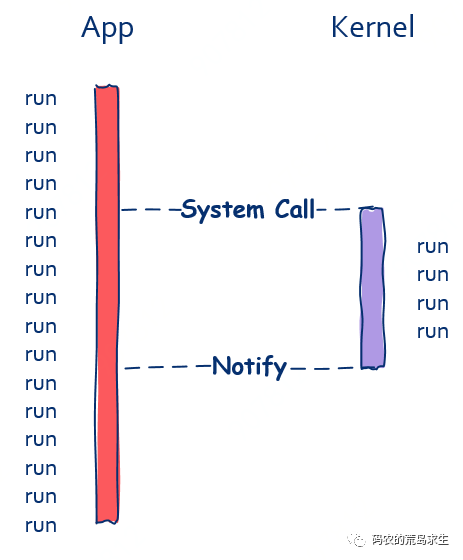
可以看到,在异步这种调用方式下,调用方不会被阻塞,函数调用完成后可以立即执行接下来的程序。
这时异步的重点就在于调用方接下来的程序执行可以和文件读取同时进行,从上图中我们也能看出这一点,这就是异步的高效之处。
但是,请注意,异步调用对于程序员来说在理解上是一种负担,代码编写上更是一种负担,总的来说,上帝在为你打开一扇门的时候会适当的关上一扇窗户。
有的同学可能会问,在同步调用下,调用方不再继续执行而是暂停等待,被调函数执行完后很自然的就是调用方继续执行,那么异步调用下调用方怎知道被调函数是否执行完成呢?
这就分为了两种情况:
- 调用方根本就不关心执行结果
- 调用方需要知道执行结果
第一种情况比较简单,无需讨论。
第二种情况下就比较有趣了,通常有两种实现方式:
一种是通知机制,也就是说当任务执行完成后发送信号来通知调用方任务完成,注意这里的信号有很多实现方式,Linux 中的signal,或者使用信号量等机制都可以实现。
另一种是就是回调,也就是我们常说的callback,关于回调我们将在下一篇文章中重点讲解,本篇会有简短的讨论。
接下来我们用一个具体的例子讲解一下同步调用与异步调用。
同步 VS 异步
我们以常见的 Web 服务来举例说明这一问题。
一般来说 Web Server 接收到用户请求后会有一些典型的处理逻辑,最常见的就是数据库查询(当然,你也可以把这里的数据库查询换成其它 I/O 操作,比如磁盘读取、网络通信等),在这里我们假定处理一次用户请求需要经过步骤 A、B、C,然后读取数据库,数据库读取完成后需要经过步骤 D、E、F,就像这样:
# 处理一次用户请求需要经过的步骤:
A;
B;
C;
数据库读取;
D;
E;
F;其中步骤 A、B、C 和 D、E、F 不需要任何 I/O ,也就是说这六个步骤不需要读取文件、网络通信等,涉及到 I/O 操作的只有数据库查询这一步。
一般来说这样的 Web Server 有两个典型的线程:主线程和数据库处理线程,注意,这讨论的只是典型的场景,具体业务实际上可会有差别,但这并不影响我们用两个线程来说明问题。
首先我们来看下最简单的实现方式,也就是同步。
这种方式最为自然也最为容易理解:
// 主线程
main_thread() {
A;
B;
C;
发送数据库查询请求;
D;
E;
F;
}
// 数据库线程
DataBase_thread() {
while(1) {
处理数据库读取请求;
返回结果;
}
}这就是最为典型的同步方法,主线程在发出数据库查询请求后就会被阻塞而暂停运行,直到数据库查询完毕后面的 D、E、F 才可以继续运行,就像这样:
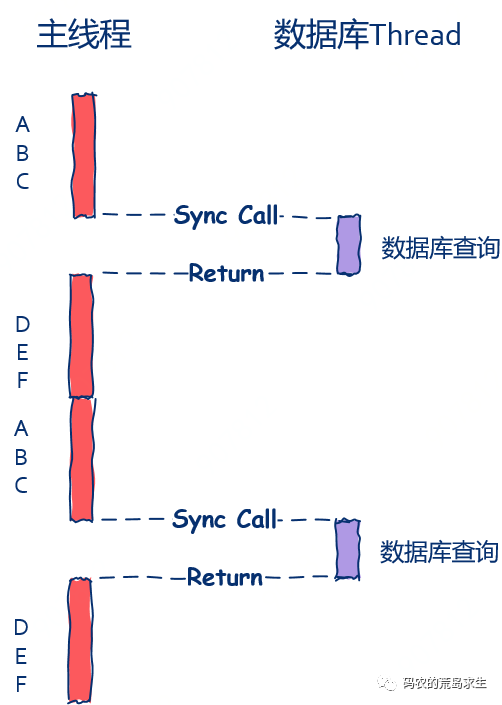
从图中我们可以看到,主线程中会有“空隙”,这个空隙就是主线程的“休闲时光”,主线程在这段休闲时光中需要等待数据库查询完成才能继续后续处理流程。
在这里主线程就好比监工的老板,数据库线程就好比苦逼搬砖的程序员,在搬完砖前老板什么都不做只是紧紧的盯着你,等你搬完砖后才去忙其它事情。
显然,高效的程序员是不能容忍主线程偷懒的。
是时候祭出大杀器了,这就是异步。
在异步这种实现方案下主线程根本不去等待数据库是否查询完成,而是发送完数据库读写请求后直接处理下一个请求。
有的同学可能会有疑问,一个请求需要经过 A、B、C、数据库查询、D、E、F 这七个步骤,如果主线程在完成 A、B、C、数据库查询后直接进行处理接下来的请求,那么上一个请求中剩下的 D、E、F 几个步骤怎么办呢?
如果大家还没有忘记上一小节内容的话应该知道,这有两种情况,我们来分别讨论。
1,主线程不关心数据库操作结果
在这种情况下,主线程根本就不关心数据库是否查询完毕,数据库查询完毕后自行处理接下来的 D、E、F 三个步骤,就像这样:

看到了吧,接下来重点来了哦。
我们说过一个请求需要经过七个步骤,其中前三个是在主线程中完成的,后四个是在数据库线程中完成的,那么数据库线程是怎么知道查完数据库后要处理 D、E、F 这几个步骤呢?
这时,我们的另一个主角回调函数就开始登场啦。
没错,回调函数就是用来解决这一问题的。
我们可以将处理 D、E、F 这几个步骤封装到一个函数中,假定将该函数命名为handle_DEF_after_DB_query:
void handle_DEF_after_DB_query () {
D;
E;
F;
}这样主线程在发送数据库查询请求的同时将该函数一并当做参数传递过去:
DB_query(request, handle_DEF_after_DB_query);
数据库线程处理完后直接调用handle_DEF_after_DB_query就可以了,这就是回调函数的作用。
也有的同学可能会有疑问,为什么这个函数要传递给数据库线程而不是数据库线程自己定义自己调用呢?
因为从软件组织结构上讲,这不是数据库线程该做的工作。
数据库线程需要做的仅仅就是查询数据库、然后调用一个处理函数,至于这个处理函数做了些什么数据库线程根本就不关心,也不应该关心。
你可以传入各种各样的回调函数。也就是说数据库系统可以针对回调函数这一抽象的函数变量来编程,从而更好的应对变化,因为回调函数的内容改变不会影响到数据库线程的逻辑,而如果数据库线程自己定义处理函数那么这种设计就没有灵活性可言了。
而从软件开发的角度看,假设数据库线程逻辑封装为了库提供给其它团队,当数据库团队在研发时怎么可能知道数据库查询后该做什么呢?
显然,只有使用方才知道查询完数据库后该做些什么,因此使用方在使用时简单的传入这个回调函数就可以了。
这样复杂数据库的团队就和使用方团队实现了所谓的解耦。
现在你应该明白回调函数的作用了吧。
如果你觉得有帮到你,请伸出你的小手帮忙分享再看一下,原创不易,你的一个在看是对博主最大的肯定,拜托大家啦。

不容易啊,容我喝口水叉会儿腰歇一歇。
我们继续。
另外仔细观察上面两张图,你能看出为什么异步比同步高效吗?
原因很简单,这也是我们在本篇提到过的,异步天然就无需等待,无依赖。
从上一张图中我们可以看到主线程的“休闲时光”不见了,取而代之的是不断的工作、工作、工作,就像苦逼的 996 程序员一样,而且数据库线程也没有那么大段大段的空闲了,取而代之的也是工作、工作、工作。

主线程处理请求和数据库处理查询请求可以同时进行,因此从系统性能上看,这样的设计能更加充分的利用系统资源,更加快速的处理请求;从用户的角度看,系统的响应也会更加迅速。
这就是异步的高效之处。
但我们应该也可以看出,异步编程并不如同步来的容易理解,系统可维护性上也不如同步模式。
那么有没有一种方法既能结合同步模式的容易理解又能结合异步模式的高效呢?答案是肯定的,我们将在后续章节详细讲解这一技术。
接下来我们看第二种情况,那就是主线程需要关心数据库查询结果。
2. 主线程关心数据库操作结果
在这种情况下,数据库线程需要将查询结果利用通知机制发送给主线程,主线程在接收到消息后继续处理上一个请求的后半部分,就像这样:
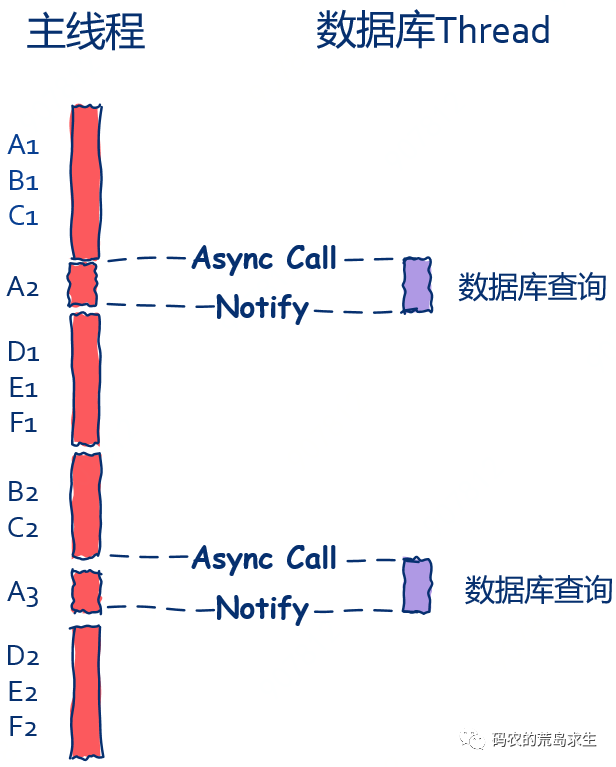
从这里我们可以看到,ABCDEF 几个步骤全部在主线中处理,同时主线程同样也没有了“休闲时光”,只不过在这种情况下数据库线程是比较清闲的,从这里并没有上一种方法高效,但是依然要比同步模式下要高效。
最后需要注意的是,并不是所有的情况下异步都一定比同步高效,还需要结合具体业务以及 IO 的复杂度具体情况具体分析。
总结
在这篇文章中我们从各种场景分析了同步与异步这两个概念,但是不管在什么场景下,同步往往意味着双方要相互等待、相互依赖,而异步意味着双方相互独立、各行其是。希望本篇能对大家理解这两个重要的概念有所帮助。
来源:公众号
作者: 码农的荒岛求生